About Me
Hi o/
I'm Paulo Feodrippe, a software engineer contractor based on SP - Brazil. I'm interested in distributed systems, development tooling and my wife (besides my little dog called Pitoco).
I've been developing systems since 2015, and working with everyone's favorite language1 since 2017.
Clojure, of course 😬
Pitoco
One project I have been working recently is Pitoco, it’s written in Clojure and was originally created with the purpose of inferring REST HTTP requests using packet capture, heavily inspired in a startup called Akita.
The first place where I tested it was in my daily job (Gravie, a healthcare startup company). At Gravie there is a legacy app in Grails (we are migrating/doing new services to/in Clojure) which exposes many REST endpoints and I wanted to understand more what's was there, this happened at the same time as I was reading some awesome posts from the Akita blog and that was the trigger which leaded to this project. Let's see how you could use it in your project.
Capturing network data
Imagine you have your server for integration or E2E tests at localhost:8005. You have no OpenAPI schema or most of the documentation is outdated, you can start tcpdump to capture packet data.
tcpdump -i lo0 'port 8005' -w dump.pcap
In some other terminal you can exercise the endpoints (e.g. by running the tests). When the exercise is finished, stop tcpdump run and check that you have a dump.pcap file created. These are your TCP packets in some binary format (I'm not a network person, so pardon my language), let's see how to process these.
Inferring schemas
In pitoco.core there is a process function which enables you to infer and output the schemas (backed by Malli) found in the dump file.
process uses Pathom 3 behind the scenes and its API is similar to the one used by Pathom, I would recommend you to check its documentation to see the possibilities (there is much more you can do!) and to understand the relationship between the input, outputs and resolvers.
See below for a example (assuming your dump file has only one valid request captured and it was from httpbin).
(ns foo
(:require
[pitoco.core :as pit]))
(pit/process {::pit/pcap-path "path/to/some/folder/dump.pcap"}
[::pit/api-schemas])
;; =>
{::pit/api-schemas '[{:path "/get"
:method :get
:host "httpbin.org"
:request-schema any?
:response-schema
[:map
[:args [:map]]
[:headers
[:map
[:Accept string?]
[:Host string?]
[:User-Agent string?]
[:X-Amzn-Trace-Id string?]]]
[:origin string?]
[:url string?]]}]}
You can not only output API schemas, but also, because of Malli, generate Open API schemas, see the test file in the Pitoco repo for some examples. Use Pathom Viz to play with the exposed Pitoco Pathom API.
When outputing API schemas, you are also able to define custom data types (e.g. using regex) and have it in the schema if applicable, so you can extend the available types for your context (e.g your system has some external id format or you divide your users based on age intervals, just define it with Malli and you are good to go), see here.
Besides the API, Pitoco also has a visualizer for the API schemas, see the image below (it even includes a diff with a previous version of a schema)
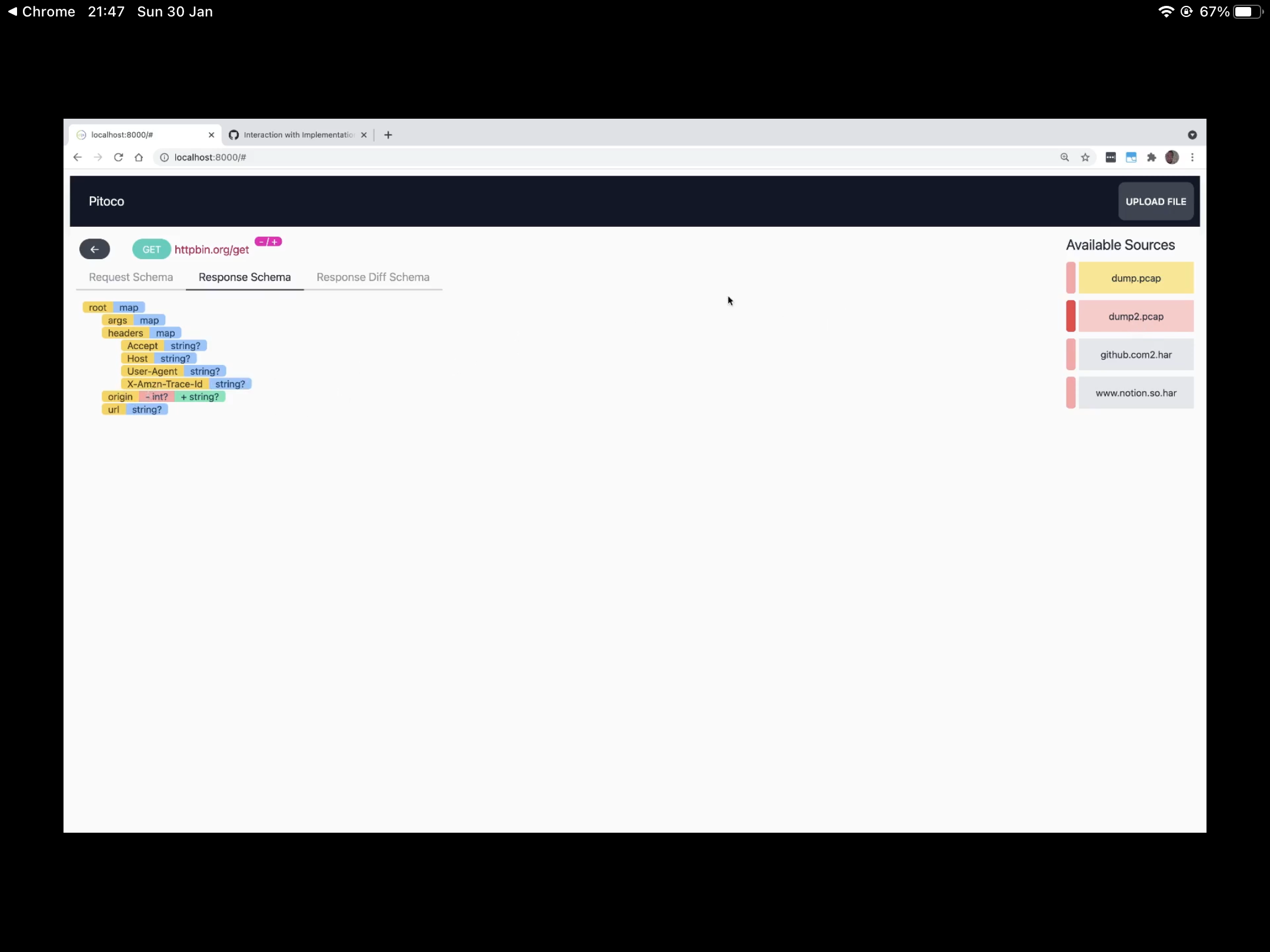
Other use cases
In Gravie we use Cypress (with Clojurescript) for our isolated front end tests (they do not talk to a server or database) and we have to mock many of requests/responses for the used endpoints (generally only once so we make a fixture out of it), they can get out of sync quickly if we don't take care of updating them. I was a let to use Pitoco to generate API schemas from the JSON files (no need to capture packets here as we already had the request/response in JSON format), one low-hang fruit would be to compare them with the generated API schemas from the server. If I do this I will try to write some new post.
Recently Pitoco added support to infer Malli schemas (not API schemas) from Clojure vars when you exercise them (e.g. when running tests after instrumentation), check a video at https://youtu.be/MloJSCl38d0. With the instrumentation we have runtime information in a static format and could, among other ideas, do the following:
- Look for usages of a keyword (output/input)
- Match similarity between schemas
- Match outputs with inputs
- Check stacktraces to find call ordering
- Create diffs among different schemas
- Show diffs for the same var using the visualizar (evolution from one schema to the other)
- Index schemas for querying
- Indicate which functions can be REPLed in isolation?
- Inline schemas into code
Well... lots of stuff to pay, let's see what's useful. Open an issue or create a PR if you have any idea as well o/